The LiquidityWell Sequenced Multicast Design Pattern
As part of our R&D work low latency trading platform, we found that the the data transport layers we were familiar with came with overheads in terms of feature sets and learning curves that we found impacted the way we wanted to do things.
So we decided to design our own product.
The brief was to create an ultra-low latency, middleware communication software which suited our specific requirements, namely speed and throughput equal to that of our matching engine. Costs were a consideration and we needed to work within a budget, being a young company, but equally we enjoy having a product that uses all our own IP and therefore was worth the investment. We also wanted what were termed “clean” access points to permit business application developers to be shielded from the messaging complexities, and feature bloat had to be kept to a minimum to enable maintainability.
We had the experience within the team and specific requirements to design to. Herein lies our experience and results.
Sequenced Multicast BUS
Sequencing Events
Sequenced data packets provide a single event stream that is consumed by all services connected to the BUS. Reliability of packet delivery is achieved using a message replay service. This is a well-established design pattern in Finance, used for high throughput, low latency solutions since around the early 2000’s. A single sequenced event stream provides for deterministic state replication, both in real time and in later replay. This is crucial in multiple areas of the business including trading, broking, compliance, risk, pricing, and regulatory obligations. Given the event stream’s role and “mission critical” status it must handle multiple, high speed publishers, offer full recovery, fault tolerance, and business continuity.
Multicast
The underlying multicast output provides simultaneous packet distribution to all subscribing components in real time. This is much faster than a point to point message broker which must duplicate messages being sent.
The fundamental pattern is then able to offer high availability of service components running in a variety of configurations such as hot-hot, hot-warm and hot–cold. Multiple publishers and multiple subscribers are supported, with fully recoverable state, distributed between multiple components.
Our Goals of Ordered Multicast
We wanted our implementation to use both hardware and software acceleration techniques wherever possible to avoid compromising our ultra-low latency Matching Engine.
Our design needed to offer a persistent, sequenced, recoverable multicast message distribution. The result gives a “real time” distributed state messaging model.
What is real time to us?
We needed to define it as it certainly differs depending on who you speak to! Our internal definition of real-time is event distribution with a median latency of below 5 microseconds between two applications layers on the BUS, lowering to 4 microseconds for a point to point solution and specialist network cards
The Components we Created
| SEQUENCER | Event receiver and sequencer with persistent SSD storage and asynchronous spooling of event files. This was important given our need for backup and recovery whilst maintaining “constant” processing rates. 64bit event sequence numbering to give us the room to decide later if we would leave it running indefinitely or reset for any convenient time period depending on the business model. For a highly available deployment, one or more standby sequencers are required, for a business continuity deployment, a third sequencer is required in a physically separate location. All of this was to be built into the design. |
| APPLICATION INTERFACE | A simple, light-weight, decoupled publisher-subscriber service API with built-in state replication and recovery. Provided as a shared object or a DLL to support multiple language technologies. The API ensures the pattern is adhered to and therefore application developers are not responsible for writing these components themselves. Topic based filtering. |
The Persistence Story
The sequencer is responsible for persistence of the event stream. Critically no information is published on the multicast channel for subscribers until a copy has been persisted in memory for subsequent recovery if required. The multicast channel therefore acts as the golden source of the event stream, and only if an event has been published on this channel by the sequencer it is deemed to exist. The persistence is achieved through in memory and asynchronous SSD storage. With real time spool file rolling to avoid file size constraints.
The Recovery Story
Recovery and message gap filling are handled between the nodes and the sequencer. The application layer is aware of the initial recovery but not the subsequent gap fills. The sequencer and nodes have a recovery ability in excess of double the main publish channel (subject to the number of nodes recovering simultaneously). The node initiates the recovery process upon start up and gap filling occurs when a gap is detected in the multicast stream. New subscriptions are paused until recovery is complete. Recovery from the sequencer is achieved through the persisted state of the event stream.
In practice this recovery rate equally permits additional applications to be launched during trading hours and catch up to real time state.
The Nodes
All the BUS connectivity, publishing, subscribing, topic filtering, buffering and recovery is taken care of within the node logic. Connection nodes offer the ability for an application developer to write business code without needing to know the engineering decisions made within the node. Language specific wrappers exist to facilitate implementation, and therefore we or any future clients can assign developers to writing business applications without the need for expertise in the lower-level communication piece.
We considered future enhancements include additional language support for the node wrappers, having written C++, Java and .Net for our requirements. It would seem sensible to extend these to a Python and Rust capability, and others too if the demand was apparent.
The Bus Logger
A log program is installed on each box where the multicast bus is available. This provides a human readable journal of all events in the order that they appeared on the bus, essential for application testing and production monitoring . The logger can match the speeds of the sequencer publishing and therefore should not fall behind. This in itself needed some detailed design and various “fast” loggers were created before we finally got what we needed.
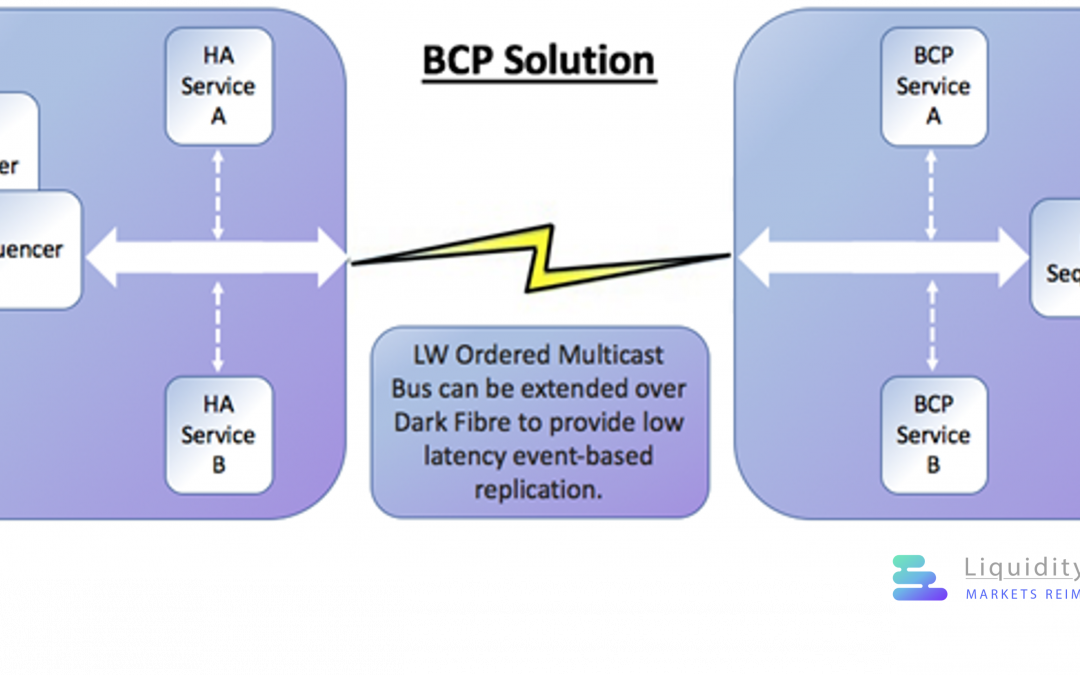
BCP Capability
Our architectural pattern idea was to be consistent even in the need for BCP. We chose the pattern to, in theory, simply extend our multicast bus over dark fibre to a remote BCP datacentre, where replicated state is constantly kept up to date. BCP applications can run in hot or warm standby mode. This is an improvement over traditional cold BCP sites that may fail to start up when required to do so.
The BCP solution can be verified at any time by activating remote BCP services.
 Benchmarking
Benchmarking
Latency benchmarking is here is at best indicative, with caveats around comparisons between solutions that are so often not like for like!
At the end of the day you really have to bring it back to the use case you are solving for and to try to focus the specific requirements for that. Our testing will continue, with more focus on statistical analysis and identify percentile outliers etc.
The current baseline should be taken as a simple guide only!
Current Baseline
Speed of a ping – Using the hardware specified below, we have baselined the round-trip time between hosts. The median was 2.58 micro-seconds when sending 200,000 messages per second. This round-trip latency measurement is from Host A to the wire to Host B back again.
Adding a service – Our Service A -> Sequencer ->Service B -Sequencer -Service A roundtrip median latency is in the order of 7 microseconds.
In our simple set up the BUS can operate, given the correct hardware configuration, with sustained message rates in the region of 200,000 messages per second, including microbursts of over 1 million MPS. Our message recovery rate for message replay has been benchmarked at 3 million MPS.
Hardware
668W Platinum Level Certified High-Efficiency Power Supply Asus PRIME Z390-A, Intel Z390, 1151, ATX, 4 DDR4, SLI/Xfire with Gigabit LAN, , HDMI, DP, Intel Core I9-9900K 1151, 3.6 GHz (5.0 Turbo), 8-Core, 95W, 14nm, 16MB, Overclockable 64GB DDR4 2666Mhz (4x16GB) 1x Samsung Evo 970 Plus M.2 1TB SSD 1x Seagate Barracuda 1TB 7200RPM HDD Intel 95W CPU Cooler
On-board Solar Flare Ultra SFN8522-PLUS – Network adapter PCIe 3.1 x8 – 10 Gigabit SFP+ x 2
We understand the point to point connection between machines will require a dedicated switch in the production delivery to ensure optimum performance and avoid microburst packet loss.
The Network Interface Cards are an important component when considering the platform for peak performance. We utilise Solar flare kernel bypass technology to provide a low latency message path between services. Choosing 40 or 100 Gb networks would further significantly lower the latency and increase the bandwidth available.
Deployment
We found that the deployment of the BUS architecture needed to be flexible, and therefore have built it with configurations to permit this, not least that we wanted our development environments to be operated in the cloud.
This came with its own challenges such as enabling multicast on AWS. We did get to the place where the deployment retains many of the features of the physically deployed solutions however it consumes less resources of the machines. For example, both the nodes and sequencer have configuration parameters to ensure they consume less memory and CPU. Equally the nodes can work on standard rather than high performance NIC’s.
We achieved the aim and the end result is that the deployment can be achieved on “bare metal”, a two VM configuration and a single VM configuration in the cloud.
Improvements to Come
Wire to Host
Faster “wire to host” for the applications that will continue to reside outside of any FPGA implementation. We are looking to write to one or more of the APIs provided by the major low latency NIC producers. A first step would be to utilise the Solar Flare low latency API (ef_vi), which we estimate will reduce 300 nanoseconds to/from the wire.
High Availability Improvements
Multiple sequencers to be operational at all times. The sequencers can run in HA pairing but would need additional work to resolve the best way to do this with the minimum impact of latency.
Some FAQ’s we have been asked and asked ourselves!
How does the BUS perform across wide area networks ?
The middleware pattern was originally designed to run on a single subnet that supports multicast. In mission-critical deployments, such as in an Exchange, the bus is deployed to a dedicated switch that is isolated from other “green zone” traffic. This removes any microbursts from unrelated traffic. For BCP, the subnet is extended to a remote datacenter using dedicated fibre. Clearly this is a “Rolls Royce” solution and is used for mission-critical deployments only.
The pattern could be used over a shared network. The network would need to support multicast. WAN traffic could be handled by a TCP bridge such a bit like the Tibco rvrd.
If the latency and throughput requirements are not as extreme as an exchange then this deployment pattern is possible.
How does the BUS perform on virtualized infrastructure?
We have recently adapted the pattern to work on AWS. AWS provides an IP_GRE tunnel POC, as well as a Transit Gateway hub-based model for multicast.
We have chosen the Transit Gateway solution as the IP_GRE tunnel has not progressed beyond a POC. The Transit Gateway essentially acts as a hub for multicast traffic and can be configured to distribute traffic to specific EC2 hosts.
We have not yet looked at the AWS bare-metal offering. If the bare metal offering allows us to have a dedicated subnet with multicast capability then we can deploy the pattern in its original configuration.
How does the BUS perform across processes that run on the same server?
We have run the system on a single box, with the loopback interface configured for multicast. The bigger issue with a single box is CPU usage. For an ultra-low latency deployment, we spin on CPUs and use CPU affinity. This does not work well if there are insufficient cores. We have therefore developed an epoll based bus that is CPU efficient. This is now a configuration option when starting the bus. We still have some minor changes to do here, but essentially this works. This is also a more sensible option for an AWS deployment.
Do you have benchmarks that include one-to-one, one-to-many, many-to-many communication for different system configurations?
We can provide these. We have not measured every permutation yet. We use multicast, and so the number of consumers makes no difference.
The interesting measurement will be the impact to outliers when multiple consumers concurrently recover missed messages.
I understand that to achieve best performance you use “active wait” in your processes and specialized network hardware. Is there a way to use “passive wait” (e.g. standard select/poll I/O wait) when ultra-low-latency is not a requirement and we want to make efficient use of hardware infrastructure? What does performance look like in this case?
We have just recently developed this for the Sequencer. There is still some work for this to be added to the node. We use “epoll”. Benchmarking is pending.
How would the middleware be deployed on hybrid infrastructure that includes physical infrastructure (e.g. co-located hardware) as well as virtual infrastructure (cloud) and dedicated network links in between?
This could be achieved using VPN, and TCP bridges. The system would need to be tuned differently, eg resend timeouts would need to be increased for publishers.
What “communication paradigms” does your middleware support? (e.g. pub/sub, request/reply, message queues, etc.)?
The paradigm is pub-sub over reliable multicast. There is a single recoverable “event stream” for all consumers. There are therefore no message queues. A consuming application, upon start-up can recover the event stream from a given sequence number, and is notified when recovery is complete and real-time messages are now flowing. We have topic filtering, to prevent applications from receiving messages that are not of interest. An application level request-response protocol can be implemented. As mentioned there are no message queues per consumer. The recoverable event stream could be considered as a single message queue for all consumers.
What adapters and APIs do you have available, to interface to your middleware? Do the APIs provide a way to define message structures and bind them to native language constructs?
The pub/sub bus “node” has been developed for Linux. The node library is written in C++. A JNI based adapter has been written to provide support for Java applications running on Linux. A .Net Core adapter has been provided for .NET applications running on Linux.
All of these use the same underlying library. Our roadmap includes a native Windows pub/sub node.
The bus provides raw bytes message transfer and is not tied to any specific message marshalling technology. For low latency applications, we use binary fixed-length messages for speed of encoding and decoding. It can just as easily carry Google Protobuf or FIX key-tag pairs.
We consider message marshalling to be a different “layer”, and there is no point in reinventing the wheel or constraining the user to a single technology. If you wish to send and receive xml, you can.
We provide a reliable recoverable stream with totally flexible content.
Can you deploy different buses for different traffic?
These are essentially different event “streams” that are independent from one another.
You can have a pre-trade bus, for various what-if scenarios and distribution of analytics eg market impact of average price due to a large order.